NIST AI Risk Management Framework (AI RMF) 1.0 概説 ~ その1

まえがき
本記事は、AISI(Japan AI Safety Institute)により翻訳された「米国NIST AI リスクマネジメントフレームワーク(RMF)の日本語翻訳版」、および、オリジナルの「NIST AI 100-1 AI Risk Management Framework (AI RMF 1.0)」をベースに、弊社にて独自の解説・加筆・修正を行っております。
AISI、およびNISTの活動に謝辞を申し上げます。
(注)NISTとは?
米国商務省参加の国立標準技術研究所(National Institute of Standards and Technology)
はじめに
近年、ディープラーニング(ニューラルネットワーク)の発達をひとつのきっかけとし、AI(機械学習)は、大きな盛り上がりを見せており、ChatGPTをはじめとする生成AIの登場により、盛り上がりは、さらに加速しています。
ただし、AI技術には、まだまだ解明されていない部分も多く、AIにかかわるリスクも同時に増大しています。
そのような背景を受けて、様々なAIに関するフレームワークや法規制が登場していますが、今回は、2023年1月に、米国NISTより発表されたAI技術のリスク管理のためのガイダンスである 「AIリスクマネジメントフレームワーク」(AI RMF) の概要を解説します。
背景と成り立ち
米国にて、2021会計年度国防授権法の一部として成立した「2020年国家人工知能イニシアチブ法」に基づいて、信頼性のあるAIシステムのためのリスク管理フレームワークを策定するため、2021年7月以降、関係者からの意見聴取などを進め、2023年1月にAI RMF 1.0を公開しました。 AIシステムを設計、開発、展開する組織、および使用する組織などが自主的に活用するよう推奨されています。
解説
全体として、NIST AI RMF は下記のように構成されています。
- エグゼクティブ・サマリー
- パート1:基礎情報
- リスクの枠組み
- オーディエンス
- AI のリスクとトラストワージネス
- AI RMF の有効性
- パート2:コアとプロファイル
- AI RFMF コア
- AI RMF プロファイル
それでは、ひとつづず説明していきます。
エグゼクティブ・サマリー
ここでは、AI テクノロジーや、それがもたらすリスク、AI のリスクマネジメント、RMF 成立の背景、目的、等を述べています。
AI リスクの特異性
ここで、特徴的なのは、「AIシステムがもたらすリスクは多くの点で独特」 であることを指摘している点です。
詳細は、AI RMF の付録Bを参照していただければと思いますが、付録Bで述べられているAIリスクでは、「予測不可能性」「不確実性」「不透明性」「複雑性」といったことが多く言及されています。
また、「適切な制御がなければ、AIシステムは個人やコミュニティにとって不公平で望ましくない結果を増幅、永続化、悪化させる可能性がある」と警鐘をならしています。
AI RMF は2部構成
さらに、このパートでは、AI RMF が2部構成であることを説明しています。
第1部では、AI RMFの基本的な考え方や想定される読者について言及しています。
また、AIのリスクとトラストワージ(Trustworthy=信頼できる、信用に値する)について分析し、トラストワージな(信頼できる)システムの特徴(妥当性と信頼性、安全性、セキュリティとレジリエンス、アカウンタビリティと透明性、説明可能性と解釈可能性、プライバシーの強化、有害なバイアスを管理した公正性)を説明しています。
第2部では、AI RMFの「コア機能」を主に説明しています。
「コア機能」とは、AIシステムのリスクに対処するために組織が守るべきルールとも言えるもので、以下の4つが定義されています。
「統治 / GOVERN(組織におけるリスク管理文化の醸成など)」
「マッピング / MAP(状況の認識とリスクの特定)」
「測定 / MEASURE(リスクの評価・分析・追跡など)」
「管理 / MANAGE(リスクの優先順位付けやリスクへの対応)」
NISTは、AIシステムのライフサイクルの各段階を通じて、継続的にリスク管理を行うべきとしています。
また、ここで、「AIアクター」 という用語が定義されています。
※ 経済協力開発機構(OECD)は、AI アクターを「AI を展開・運用する組織や個人を含め、AI システムのライフサイクルにおいて積極的な役割を果たす者」と定義している。(OECD (2019) Arti fi cial Intelligence in Society —OECD iLibrary)(付録 A 参照)
パート1:基礎情報
1. リスクの枠組み
1.1. リスク、インパクト(影響)、危害の理解と対処
ここでは、AI RMF における「リスク」について説明しています。
AI RMF において、「リスク」とは、ネガティブなものだけでなく、ポジティブな影響も含んでおり、リスクマネジメントプロセスもそれに対応したものとなっています。
また、AI RMF は、新たなリスクの出現に際しても対応できるように設計されていると述べています。
さらに、AIシステムに関連する潜在的な弊害の例として、下記をあげています。
- 人への危害
- 個人: 個人の自由、権利、身体的・心理的安全、経済的機会に対する危害
- 集団/コミュニティ: ある集団に対する差別など、集団に対する危害
- 社会:民主主義への参加や教育へのアクセスに対する危害
- 組織への危害
- 組織の事業運営に対する危害
- セキュリティ侵害や金銭的損失による組織に対する危害
- 組織の評判に対する危害
- エコシステムへの危害
- 相互に関連し、依存し合っている要素や資源に対する危害
- グローバルな金融システム、サプライチェーン、または相互に関連するシステムに対する危害
- 天然資源、環境、地球に対する危害
1.2. AIリスクマネジメントの課題
1.2.1 リスクの測定
AIのリスクや障害は、定義が不十分であったり、十分に理解されていないため、定量的・定性的に測定することが困難であることを述べ、さらにリスク測定の課題として下記をあげています。
サードパーティのソフトウェア、ハードウェア、データに関するリスク
・リスクが、サードパーティのデータ、ソフトウェア、ハードウェアそれ自体と、その使用方法の両方から出現し、リスク測定を複雑にする可能性。
・AI システムを開発する組織とデプロイまたは運用する組織が使用するリスク測定基準や方法論が一致しない可能性。
・AI システムを開発する組織が、使用したリスク測定基準や方法論について透明性を持たない可能性。
顕在化するリスクの追跡
・新たなリスクを特定・追跡し、それを測定する手法を検討することで、組織のリスクマネジメントの取り組みは強化される。
・AI システムのインパクトアセスメントのアプローチは、AI アクターが特定の文脈における潜在的な影響や危害を理解するのに役立つ。
信頼できるメトリクスの可用性
・現在のところ、リスクと信頼性に関する堅牢で検証可能な測定方法、および様々な AI のユースケースへの適用に関するコンセンサスが得られていない。
・ネガティブなリスクや危害を測定しようとする場合、潜在的な落とし穴として、測定基準の開発はしばしば組織的な取り組みであり、根本的な影響とは無関係な要因を不注意に反映してしまう可能性がある。
・測定アプローチが単純化されすぎたり、ゲーム化されたり、重要なニュアンスを欠いたり、予期せぬ形で信頼されるようになったり、影響を受ける集団や文脈の違いを説明できなかったりすることもある。
AI のライフサイクルの様々な段階におけるリスク
・AI のライフサイクルの初期段階におけるリスクの測定は、後期段階におけるリスクの測定とは異なる結果をもたらす場合がある。
・ある時点では潜在的なリスクであっても、AI システムが適応し進化するにつれて増大するリスクもある。
・AI のライフサイクル全体を通じて、AI アクターが異なるリスク観を持っている場合がある。例えば、事前に学習されたモデルなど、AI ソフトウェアを利用可能にする AI 開発者は、その事前に学習されたモデルを特定のユースケースにデプロイする責任を負う AI アクターとは異なるリスク視点を持つ可能性がある。
そのようなデプロイヤは、その特定の用途が、最初の開発者が認識したリスクとは異なるリスクを伴う可能性があることを認識していない場合があります。すべての AI アクターは、目的に適合した信頼できる AI システムを設計、開発、デプロイする責任を共有します。
現実世界におけるリスク
・実験室や管理された環境で測定されたリスクは、現実世界で現れるリスクとは異なる場合がある。
不可解さ
・不可解な AI システムはリスク測定を複雑にする可能性がある。
・不可解さとは、AI システムの不透明な性質(説明可能性や解釈可能性の制限)、AI システムの開発やデプロイにおける透明性や文書化の欠如、あるいは AI システムに内在する不確実性の結果である場合がある。
人間のベースライン
・例えば意思決定など、人間の活動を補強または代替することを意図した AI システムのリスクマネジメントには、比較のための何らかの基準値が必要。
・AI システムは人間とは異なるタスクを実行し、異なるタスクを実行するため、これを体系化することは困難。
1.2.2 リスク許容度
ここでは、AI RMF における「リスク許容度」について述べています。
特徴的なのは、AI RMFは「リスクの優先順位付けには使用できるが、リスク許容度を規定するものではない」としている点です。
また、リスク許容度は、極めてケース・バイ・ケースであるとも述べています。
1.2.3 リスクの優先順位付け
ここでは、AI RMF における「リスクの優先順位付け」について述べています。
特徴的なのは、「すべてのインシデントや障害を排除できるわけではない」ことを強調している点であり、「ネガティブなリスクを完全に排除しようとする」のではなく、優先順位を付けて対応するよう述べています。
また、「AI システムが、個人を特定できる情報のような機密または保護されたデータで構成される大規模なデータセットで学習される場合や、AI システムの出力が人間に直接的または間接的な影響を与える場合などには、より高い初期優先順位付けが求められる可能性がある」ことに触れています。
1.2.4 組織統合とリスクマネジメント
ここでは、組織として、どのようにAIリスクに対処するべきかが述べられています。
2.オーディエンス
AI システムのライフサイクル
AI RMF では、AI システムのライフサイクルを下図のように表現しています。
※ この図は、OECD の開発したフレームワークにNISTが修正を加えたものです。
(OECD (2022) OECD Framework for the Classification of AI systems - OECD Digital Economy Papers)
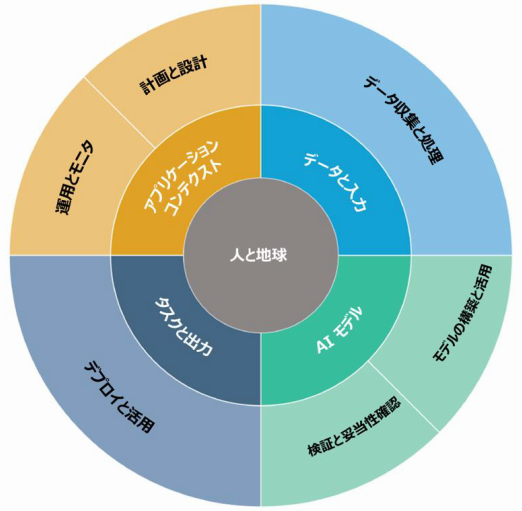
内側の 2 つの円:AI システムの主要な次元
外側の円: AI のライフサイクルの段階
理想的には、リスクマネジメントの取り組みは、「アプリケーション コンテクストにおける計画と設計の機能から始まり、AI システムのライフサイクル全体を通じて実行される」としている。
次の図では、AIシステムのライフサイクルの各次元における代表的な AI アクターを示しています。(詳細は付録 A を参照)
この図では、テスト、評価、妥当性確認、および検証(Test, Evaluation, Validation and Verification: TEVV)プロセスの重要性を強調し、AI システムの運用コンテクストを一般化しています。
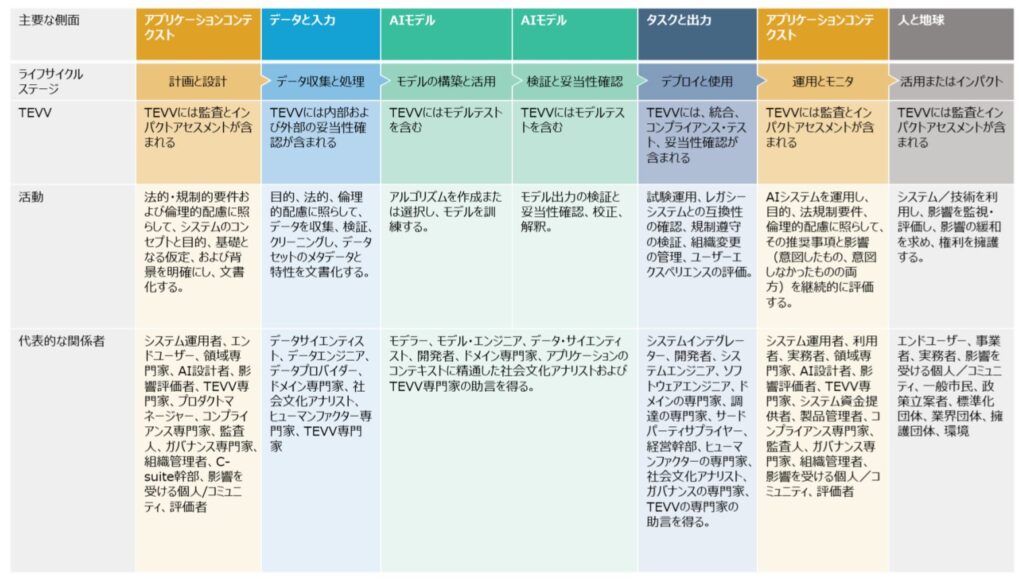
3. AI のリスクと信頼できるAI(トラストワージネス)
AI RMF では、信頼できるAIの特徴を下記の図で表しています。
(※ 妥当性と信頼性はトラストワージの必要条件であり、他のトラストワージの特性のベースとして示されています。また、アカウンタビリティと透明性は、他のすべての特性に関連するため、縦長の枠で示されています。)
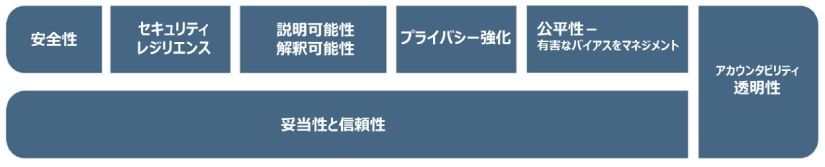
ここでは、「信頼できるAI」とはどのようなものなのか?「信頼できるAI」をどのように考えるべきか等について述べたあと、NIST AI RMF の考える「信頼できるAI」の各特徴について説明しています。
また、「信頼できるAI」の各特徴(特性)には、多くの場合、トレードオフの関係が発生するので、それぞれに個別に対処しても、必ずしも「信頼できるAI」にはならないこと、各特性が相互に影響しあうこと、各特性のバランスが重要であることを繰り返し述べています。
また、AI の信頼性特性に関連する具体的な指標と、それらの指標の正確な閾値を決定する際には、人間の判断が採用されるべき、であることにも触れています。
さらにAIの信頼性特性の理解と扱いは、AI のライフサイクルにおける AI アクターの特定の役割によって異なり、どのような AI システムであっても、AI の設計者や開発者は、その特性についてデプロイヤと異なる認識を持っていることをに認識しておくべきだと述べています。
3.1 妥当性と信頼性
妥当性とは、システムが意図されたとおりに動いているかどうかを指します。
信頼性とは、システムが故障せずに正常に動いているかどうかを指します。
また、正確性と堅牢性は AI システムの妥当性と信頼性に寄与し、また、AI システムでは対立関係にある場合(相反する場合)があります。
正確性とは、観測・計算・推定の結果が、正しい値(または正しいと認められた値)に近いかどうかを指します。
堅牢性とは、システムが想定された用途と同じように動作することだけでなく、想定外の環境で動作する場合に、人々への潜在的な危害を最小限に抑えるような方法で動作するかどうかを指します。
AI システムの妥当性と信頼性は、システムが意図したとおりに動作していることを確認する継続的なテストやモニタリングによって評価されます。
3.2 安全
安全性とは、AIシステムが、人の生命、健康、財産、または環境を危険にさらすことがないことを指します。
AI システムの安全性は、以下の方法を通じて実現・改善されます:。
- 責任ある設計、開発、デプロイの実践
- システムの責任ある使用に関するデプロイヤーへの明確な情報
- デプロイヤーとエンドユーザによる責任ある意思決定
- インシデントの経験的証拠に基づくリスクの説明と文書化
3.3 セキュリティとレジリエンス
レジリエンスとは、予期しない不利な事象が発生した際に、変化に耐え、 その機能と構造を維持できる、または、正常な状態に回復する能力のことを指します。
予期せぬ不利な事象や変化には、データソースに関することに限らず、モデルやデータの予期せぬ使用や敵対的な使用(あるいは乱用や誤用)も含まれます。
また、セキュリティとレジリエンスは関連していますが、異なる特性です。
一般的なセキュリティ上の懸念として、次のようなものがあります。
敵対的な使用、データポイズニング、AI システムのエンドポイントを介したモデル、学習データ、その他の知的財産の流出
セキュリティの一例として、不正アクセスや不正使用を防止する保護メカニズムによって機密性、完全性、可用性を維持することがあげられます。
セキュリティにはレジリエンスが含まれるだけでなく、攻撃を回避、防御、対応、回復するためのプロトコルも含まれます。
3.4 アカウンタビリティ(説明責任)と透明性
信頼できるAI は、アカウンタビリティ(説明責任)にかかっています。
また、アカウンタビリティ(説明責任)は透明性を前提としています。
透明性とは、AIシステムを使用する個人が、そのAIシステムを使用していることを認識しているかどうかにかかわらず、そのAI システムと出力に関する情報を利用できる度合いを指します。
具体的には、AI のライフサイクルの段階に応じた適切なレベルの情報へのアクセスが提供されているかどうかです。
アカウンタビリティ(説明責任) と透明性の範囲は、設計上の意思決定、トレーニングデータからモデルのトレーニング、モデルの構造、意図されたユースケース、いつ、どのように、実装、実装後の変更が行われたか、エンドユーザの決定が、誰に対して行われたかにまで及びます。
透明性を有するシステムが必ずしも正確で、プライバシーが強化され、安全で、公平なシステムであるとは限りません。しかし、透明性のないシステムがそのような特性を持っているかどうかを判断することは困難です。
AI のリスクとアカウンタビリティ*:の関係は、文化的、法的、分野的、社会的**な文脈によって異なります。
トレーニングデータの出所を明らかにすることは、透明性とアカウンタビリティの向上に寄与します。
3.5 説明可能性と解釈可能性
説明可能性とは、AI システムの動作の基礎となる仕組みの表現を指します。
解釈可能性とは、設計された目的にそった AI システムの出力の意味を指します。
説明可能性と解釈可能性を考えるうえでの前提として、ネガティブなリスクに対する認識は、システムの出力の適切な、または正しい理解の欠如に起因するという仮定があります。
説明可能性の欠如によるリスクは、AI システムがどのように機能するかを、ユーザの役割、知識、スキルレベルなどの個人差に合わせて説明することで対処できます。
解釈可能性に対するリスクは、多くの場合、AI システムが特定の予測や推奨を行った理由の説明を伝えることで対処できます。
※ 下記URLから、より詳細が説明である「説明可能な人工知能の 4 つの原則」および「人工知能における説明可能性と解釈可能性の心理学的基礎」を参照することができます。
https://www.nist.gov/artificial-intelligence/ai-fundamental-research-explainability
透明性、説明可能性、解釈可能性は、互いに支え合う特性で、それぞれが、下記のような疑問に答えます。
透明性:システムで、何が起こったか
説明可能性:システムで、どのようにそれが決定されたか
解釈可能性:システムによって、なぜそれが決定されたか、そしてそれがユーザーにとって、どのような意味を持つのか
3.6 プライバシー強化
プライバシー強化とは、一般に、人間の自律性、アイデンティティ、尊厳を保護するのに役立つ規範と慣行を指します。これらの規範と実践は、一般に、侵入からの自由、観察の制限、または個人のアイデンティティの側面 (身体、データ、評判など)の開示またはコントロールに同意する個人の主体性に対処します。
プライバシーに関連するリスクは、セキュリティ、バイアス、透明性に影響を与える可能性があり、これらの他の特性とのトレードオフを伴います。
3.7 公平性 - 有害なバイアスのマネジメント
※ 公平性に対する認識は文化によって異なり、また用途によって変化する可能性があるため、公平さの基準は複雑で定義が難しい場合があります。また、有害なバイアスが緩和されたシステムが必ずしも公平ではありません。
NIST は AI のバイアスを下記の3 つの主要カテゴリーに分類。
※ これらはいずれも、先入観、偏見、差別的な意図がなくても発生する可能性があります。
系統的バイアス
AI のデータセット、AI ライフサイクル全体にわたる組織の規範、慣行、プロセス、AI システムを使用する広範な社会に存在する可能性がある。
計算および統計的バイアス
AI のデータセットやアルゴリズムのプロセスに存在する可能性がある。
多くの場合、代表的でないサンプルによる系統的エラーに起因する。
人間の認知的バイアス
個人や集団が AI システムの情報をどのように認識して意思決定を行うか、あるいは不足している情報を補うか、あるいは人間が AI システムの目的や機能についてどのように考えるかに関連している。
人間の認知的バイアスは、AIの設計、実装、運用、保守を含む、AIのライフサイクルとシステム使用にわたる意思決定プロセスに遍在している。
バイアスは様々な形で存在し、私たちの生活に関する意思決定を支援する自動化されたシステムに根付いている可能性があります。
バイアスは必ずしもネガティブな現象ではありませんが、AI システムはバイアスのスピードと規模を増大させ、個人、グループ、コミュニティ、組織、社会に対する危害を永続させ、増幅させる可能性があります。
また、バイアスは、社会における透明性や公平性の概念と密接に関連しています。
その2へ続きます。(現在、準備中)

