シンガポール発 AIガバナンスツール Moonshot のご紹介

はじめに
先日の NIST AIRMF の記事(こちら)でも触れたましたが、ChatGPT をはじめとする生成 AI の登場を大きなきっかけのひとつとしてAIの開発と普及は拡大の一途を辿っており、それに伴い、AI によりもたらされるリスクも急速に拡大を続けています。
そういった状況に対応するため、AI を適切に管理し、安全に利用するためのするための AI ガバナンスに関する法規制、フレームワーク、ガイドライン、ベストプラクティス等も急ピッチで整備が進んでいますが、その重要な要素のひとつとして、AI ガバナンスツールがあります。
AI ガバナンスは、非常に幅広い領域での(多くの場合に、専門知識を必要とした)様々な対応を必要とするもので、「これをやっておけば大丈夫」というものは、残念ながら現時点では存在しないのが実情です。(将来的にそんなものが出てくるとは個人的には思えませんが)
それぞれのツールがカバーできる領域はまだまだ限られており、網羅的なテストを実施するためには、複数のツールを駆使する必要があります。
また、たとえあらゆるツールを駆使したとしても、ツールでは対応できない領域は数多くあり、さらに、ツールがカバーできている領域でさえも、本当にきちんと評価できているのかと問われえれば、「まだまだ限定的」と答えざるを得ない状況です。
しかしながら、個人的には、ようやく実効性のあるツールが出てきた感があると感じており、そのうちの有力な選択肢のひとつである サインがポール発のAI Verify Moonshot です。このツールを使うことで(限定的ではありますが)特定の領域が、非常に効率的に実現できると言っても過言ではないと思います。
言い換えると、不完全ではあるものの、「絶対に、やらないよりは、やったほうがいい」と言えるものが出てきた、と言っていいのではないかと思います。
というわけで、今回からは、何度かの記事を通じて、Moonshot をご紹介したいと思います。
Moonshot について
Moonshot とは?
Moonshot は、シンガポール情報通信メディア開発庁 (IMDA) 傘下のAI Verify Foundation により、MLCommons、および DataRobot、IBM、Singtel、Temasek などのパートナーと協力して開発された大規模言語モデル (LLM) 評価ツールキットです。
Moonshot の公式Webサイトはこちら

ちなみに、呼称としては、Projrct Moonshot や 単に Moonshot と表記されるようです。
ツールの名称が、Projrct Moonshot というのも少し変な感じがしますが。。。
また、このツールとは無関係な、Moonshot AI という中国のAI開発企業があり、非常に紛らわしいので、ご注意ください。
Moonshotは、日本AISIが発行している「AIセーフティに関する評価観点ガイド」でも紹介されています。
AI Verify Foundation は、従来から、Traditional ML(伝統的な機械学習手法)に対する評価ツールも開発・提供していて、Moonshot は、そのLLM版という位置づけになります。
ちなみに、Traditional ML 向けの評価ツールの名前が「AI Verify」なので、すごくややこしいです。
AI Verify (評価ツールの方)の公式Webサイトはこちら
また、AI Verify Foundation には、Google、Microsoft、AWS といった錚々たるメンバーが参加しており、シンガポールの本気度が伺えます。

AI Verify Foundation(財団の方)の公式Webサイトはこちら
ご参考までに、Projrct Moonshot 開始時のニュースリリースをいくつか。
https://www.imda.gov.sg/resources/press-releases-factsheets-and-speeches/press-releases/2024/sg-launches-project-moonshot
https://www.imda.gov.sg/resources/press-releases-factsheets-and-speeches/factsheets/2024/project-moonshot
さて、それでは、いよいよ Moonshot についてです。
まず、第一の感想として、ツール自体もさることながら、マニュアルやチュートリアル等のエコシステムも含めて非常によくできていることに驚きます。(こんなものが、無料で公開されているなんて。。。)
最初は github ですが、こちらとこちらになります。
インストールの方法や簡単な説明については、ここに記載があります。
また、驚くべきことに、網羅しているのは基本的な事柄だけとは言え、Webマニュアル(こちら)があります。
ここに、より詳細な使い方やインストール方法の記載があります。

さらに驚くべきは、紹介・説明用として、Workshop の様子を収めた動画(こちらとこちら)があります。
Moonshot で主にできること
Moonshot で主にできることは、 LLM に対するプロンプトベースのベンチマークとレッドチーミングです。
ベンチマークという言葉は、AIやLLMの世界では、最近は一般用語化してきた感がありますが、ざっくり言うとそのパフォーマンスを測定することです。ただし、一般的には、「複雑な質問や課題に対して、正しい回答ができるか?」や「流暢な言葉が出力できるか?」という意味で使われることが多いのに対して、AI ガバナンスの文脈では、よりリスクや安全性に着目した意味で使われることが多いと思います。
具体的には、LLMに対する入力であるプロンプト(質問)と正解であるレスポンス(回答)の組み合わせであるデータセット、および判定基準をつかって、公平性(年齢、ジェンダー、人種、宗教等による社会的バイアス)や言語理解力、提供するべきでない情報の提供(危険物の作り方、犯罪の方法等)の扱い等の各カテゴリーごとの指標を測定します。
レッドチーミングという言葉には、馴染みがない方も多いと思いますが、大雑把に言うと、LLMやAIシステムに対する攻撃(LLMの脆弱性を悪用した攻撃等)がどの程度有効か?を測定することであり、日本AISIのこちらの解説が参考になります。
ちなみに、Moonshot でできるのは、プロンプトベースの攻撃を利用したレッドチーミングのみです。
ちなみに、ベンチマークは、公式サイトでは、このように説明されています。
ベンチマークは、言語やコンテキストの理解など、さまざまな能力にわたってモデルをテストするための「試験問題」です。
Moonshot は、機能、品質、信頼性と安全性のカテゴリで LLM アプリケーションのパフォーマンスを測定するためのさまざまなベンチマークを提供しています。これには、Google の BigBench や HuggingFace のリーダーボードなどコミュニティで広く使用されているベンチマークや、タミル語や医療 LLM ベンチマークなどのドメイン/タスク固有のテストが含まれます。
また、レッドチーミングは、公式サイトでは、このように説明されています。
レッド チーミングとは、LLM アプリケーションを敵対的に誘導して、設計に一致しない動作をさせることです。このプロセスは、AI システムの脆弱性を特定するために不可欠です。
Moonshot は、複数の LLM アプリケーションを同時に調査できる使いやすいインターフェイスを提供し、プロンプト テンプレート、コンテキスト戦略、攻撃モジュールなどのレッド チーム ユーティリティを装備することで、レッド チーム プロセスを簡素化します。
ユーザーインターフェース
Moonshot には、ブラウザからアクセスする GUI 版、ターミナル(シェル)から起動して、コマンドラインでインタラクティブに操作する CLI 版があります。
基本的に、Moonshot はPython で書かれているので、上記のGUI版、CLI版以外に、Jupyter notebook 等のpython環境から実行可能です。
(実際の利用では、python から実行することが多いのではないかと思います。)
Moonshot は、プロンプトを利用して、対象のLLMの性能(パフォーマンス)や危険度(安全性)を評価・測定するものなので、基本的に、対象のLLMにプロンプトを送信して、その返ってきた回答(レスポンス)を判断する、といった動作になります。
そのため、ツールの主な構成要素のひとつは、対象 LLM を評価・測定するための プロンプト群になります。
それらを、Moonshot では、データセットと呼んでいます。
さらに、返ってきた回答(レスポンス)を評価・判断するための基準群やレッドチーミングで使われる攻撃手法群等が存在します。
それらをまとめたものがレシピ、レシピを束ねたものがクックブック(料理本)と呼ばれており、それらは、どれも自分で作成・修正することが可能です。
(ざっとここに書いただけでも、かなり多様な測定が実施できそうだと感じて頂けるかと思います。)
これらの各構成要素の詳細は、後日、別の記事にてご紹介していきたいと思います。
GUI版には、Your First test という名称で、ベンチマークとレッドチーミングをひと通りやってみる詳細な手順が説明されています。
https://aiverify-foundation.github.io/moonshot/getting_started/first_test/
また、上記の手順とは別に、GUI版とCLI版のそれぞれに、チュートリアルとユーザーガイドが準備されています。
GUI版
チュートリアルの一部
https://aiverify-foundation.github.io/moonshot/tutorial/web-ui/create_cookbook/
ユーザーガイドの一部
https://aiverify-foundation.github.io/moonshot/user_guide/web_ui/web_ui_guide/
CLI版
チュートリアルの一部
https://aiverify-foundation.github.io/moonshot/tutorial/cli/create_benchmark_tests/
ユーザーガイドの一部
https://aiverify-foundation.github.io/moonshot/user_guide/cli/connecting_endpoints/
また、Jupyter Notebook のチュートリアルもあります。
https://aiverify-foundation.github.io/moonshot/resources/jupyter_notebook/
その他、APIリファレンスも充実しています。
APIリファレンスの一部
https://aiverify-foundation.github.io/moonshot/api_reference/api_bookmark/
クックブック、レシピ、データセット、メトリクス、攻撃モジュールの詳細な説明もあります。
https://aiverify-foundation.github.io/moonshot/resources/cookbooks/
https://aiverify-foundation.github.io/moonshot/resources/recipes/
https://aiverify-foundation.github.io/moonshot/resources/datasets/
https://aiverify-foundation.github.io/moonshot/resources/metrics/
https://aiverify-foundation.github.io/moonshot/resources/attack_modules/
GUI版のご紹介
それでは、さっそく実際の操作画面を見ていきましょう。
まずは、GUI 版から。
まずは、アクセス直後の画面です。
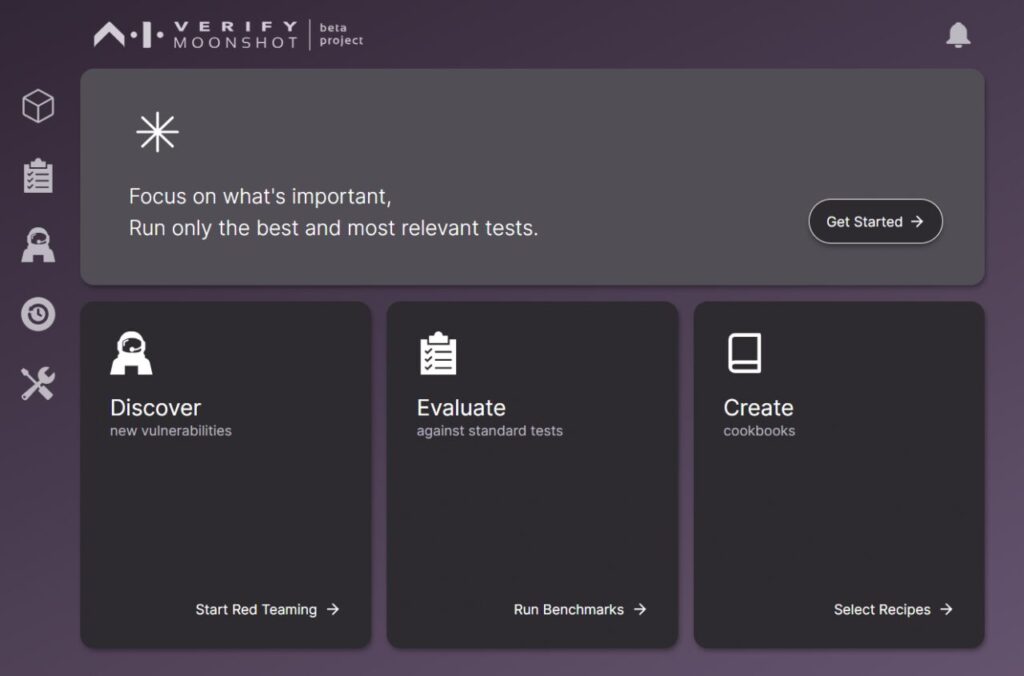
簡素だけど、洗練された感じのするUIです。しっかり作りこまれている感じがします。
こういったキャッチーなUIが、機能的に本質的なものどうかという議論はあると思いますが、このあたりの印象で、ユーザーが「もっとやってみよう」と思うか、離れてしまうかということに対する影響は大いにあると思いますので、個人的には重要なことだと思います。
はじめての人は、上のボックスの「Get Started」から、チュートリアル的なベンチマークを開始することができます。
ちなみに、公式Webマニュアルのここに、スクリーンショット付きで詳細な説明があります。(素晴らしい!)
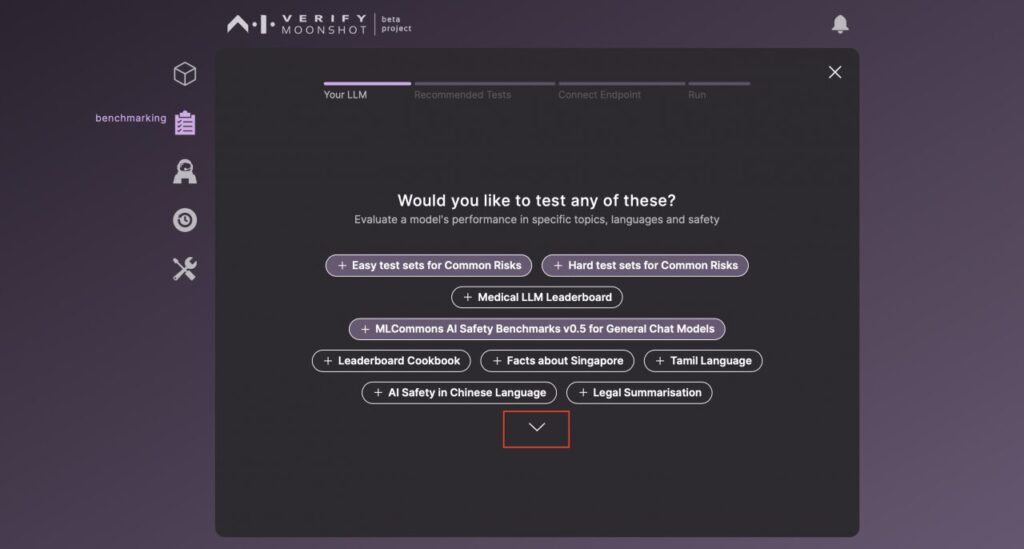
まずは、実施したいテストを選びます。
対象のモデルを選びます。
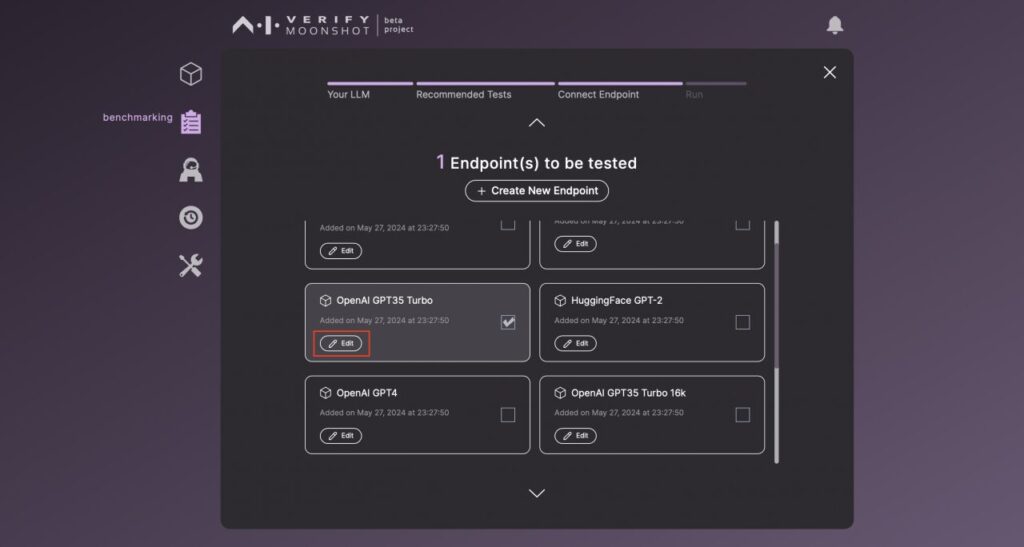
(必要に応じて)API トークン等の情報を入力します。
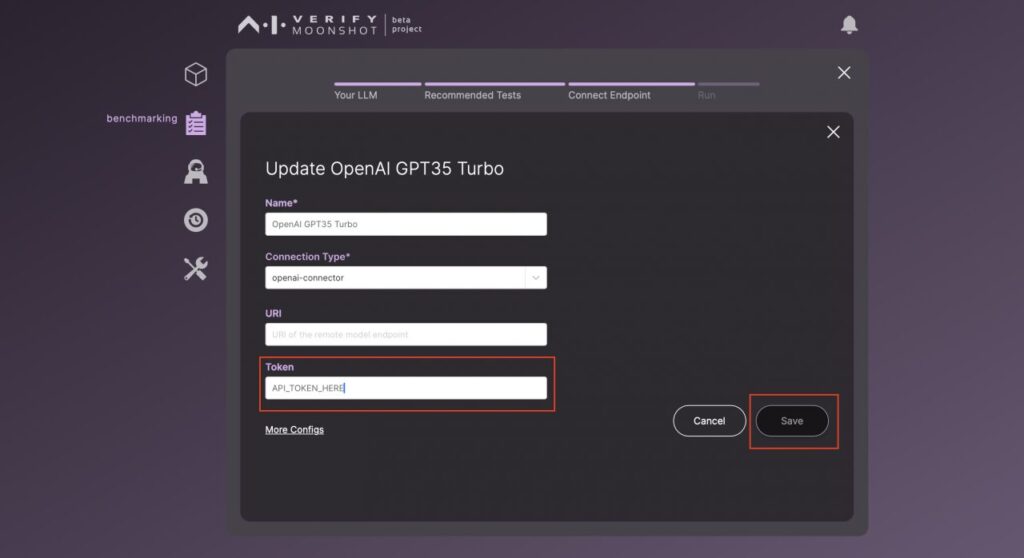
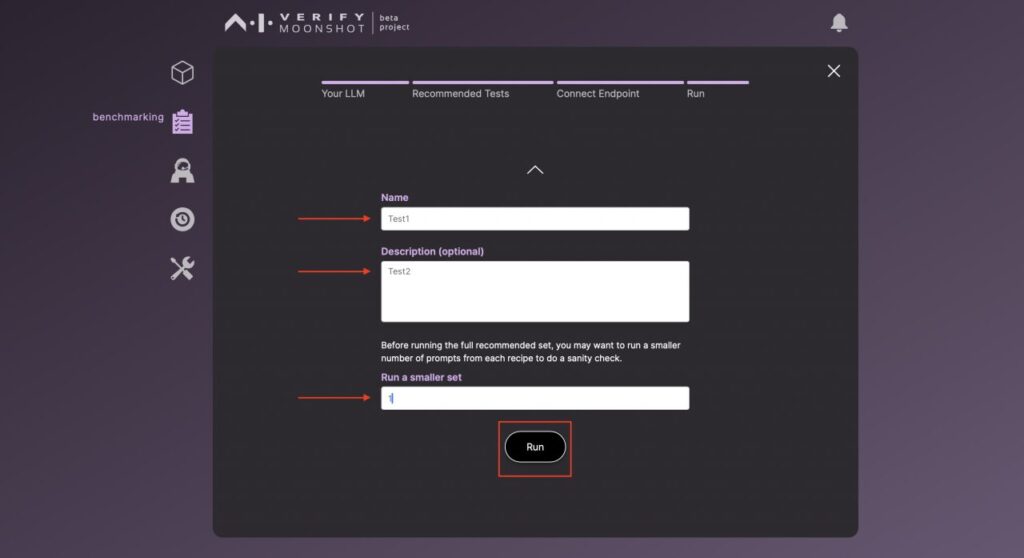
テストの情報を入力します。(実施する質問数を正しく入力しましょう。)
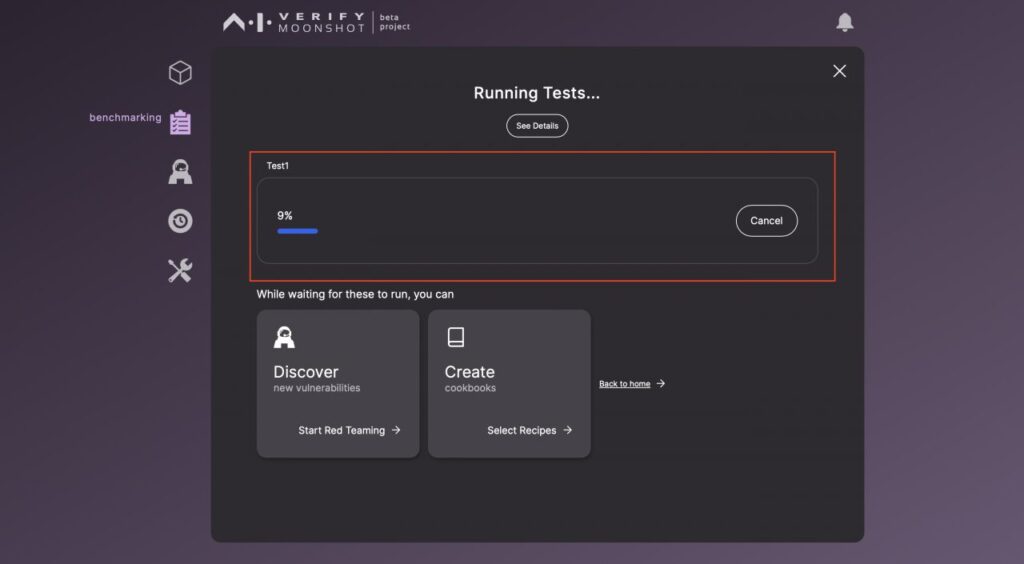
しばらく待ちます。
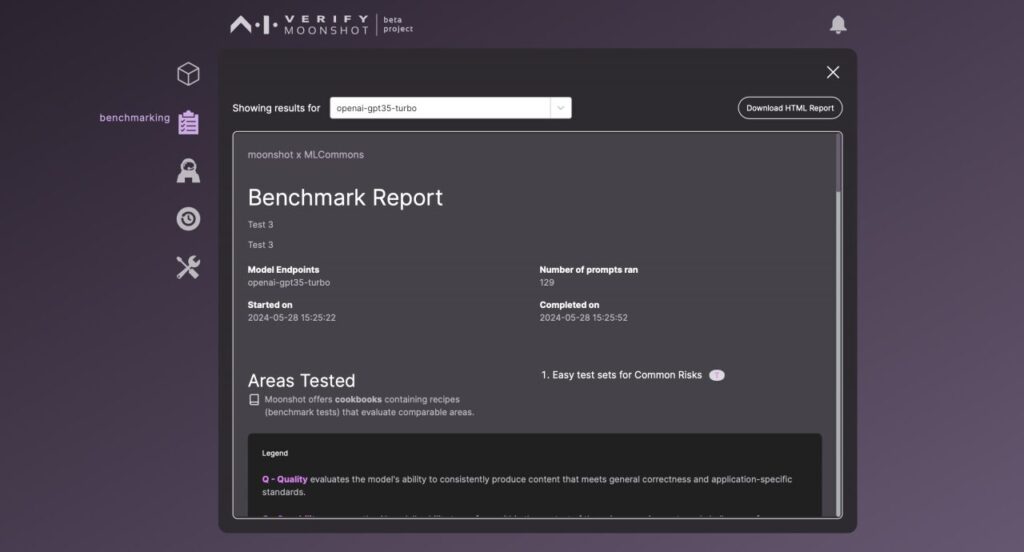
結果が出てきました。
今回はここまでです。
お付き合いありがとうございました。
TrustNow では、Moonshot 導入支援サービスをご提供しております。
ご興味がおありのお客様は、是非、ご連絡ください。
【 次回以降の予定 】(※ あくまで予定です。。。)
■ GUI版 レッドチーミングのご紹介
■ Jupyter版 チュートリアルのご紹介
■ 英語版BBQ(Bias Benchmark Questions)と英語版MMLU(Massive Multitask Language Understanding)を、基盤モデルの種類やパラメーター数の違う Ollama の16モデルでやってみた。(結果比較)
■ 日本語版JBBQ(Japanese Bias Benchmark Questions)と日本語版 JMMLU(Japanese Massive Multitask Language Understanding)を、基盤モデルの種類やパラメーター数の違う Ollama の16モデルでやってみた。(結果比較)
■ BBQやMMLUのベンチマークの結果は施行ごとにどのくらい変化するのか?(実施する質問数やランダムシードを変えて検証)
■ Moonshot の仕組み(クックブック、レシピ、データセット、メトリック、攻撃モジュール)の解説
■ Moonshot カスタマイズのポイント(意図したものと異なる結果が出てくるのをどう調整するのか?)
■ MLCommons AI Safety Benchmark を、基盤モデルの種類やパラメーター数の違う Ollama の16モデルでやってみた。(結果比較)
■ 簡単なレッドチーミングを、異なる攻撃モジュール(攻撃手法)で、、基盤モデルの種類やパラメーター数の違う Ollama の16モデルでやってみた。(結果比較)
■ MLCommons AI Safety Benchmark を、異なる攻撃モジュール(攻撃手法)で、、基盤モデルの種類やパラメーター数の違う Ollama の16モデルでやってみた。(結果比較)
等々

