Data Discoveryでどこまでできる?マイナンバー検索を試してみた!

はじめに
今日では、企業の保有するデータとその利活用が企業の成否を決定するといっても過言ではありません。
しかしながら、多くの企業は、それに伴い発生するデータ資産の管理業務と責任に頭を悩ませています。
特に、個人情報や企業秘密を含むデータの不適切な取り扱いは情報漏洩とそれにより発生するリスクを大きくするため、適切な保護対策が必要です。
OneTrust 社の Data Discoveryは、企業内に存在するマイナンバー、人名、クレジットカード番号、見積書、設計書などの様々な機密データを検出し、ラベル付けやタグ付けすることによって、企業の適切なデータ管理を支援します。
本記事では、実例としてマイナンバー検出を例に、その実効性や条件、網羅性について検証し、「検出精度は?」「どんな条件で検出可能か?」といった皆様の疑問にお答えします。
OneTrust Data Discoveryとは?
OneTrust Data Discovery は、企業で一般的に利用される企業向けデータベース、ファイルサーバー、クラウドストレージ、SaaSなどに存在する個人情報や企業秘密などの機密情報を、様々な条件に応じて柔軟、かつ広範囲に特定します。従来の方法では見つけ出すことが困難だったこれらの情報も、OneTrust Data Discoveryを利用することで効率的に検出できます。
OneTrust Data Discoveryは、特にマイナンバー、クレジットカード番号のような特定のパターン(規則性)を持つ情報の検出が得意ですが、検出対象のデータをリスト化した辞書情報を持たせることができるため、パターン化することの難しい住所や氏名のような情報も検出することが可能です。
さらに、OneTrust Data Discoveryでは、マイナンバー、クレジットカード番号、メールアドレス、電話番号、日本の住所、日本の銀行口座番号など、多くの企業や組織で要求されるであろう個人情報や機密情報を検出するための条件の多くが、事前組込の「分類子」としてあらかじめ登録されており、お客様が複雑な設定をすることなくお使いいただけます。
OneTrust Data Discovery では、上記のようなパターンや辞書情報のような検出条件を指定するのに、「分類子」と「分類プロファイル」を使います。「分類子」を使って実際の条件を指定し、それらの「分類子(複数または単数)」を束ねるのが「分類プロファイル」になります。実際のスキャンの際には「分類プロファイル」を指定しますが、この2層構造により、何度も同じ設定をすることなく複雑な条件の指定が可能になります。
「分類子 (Classifier)」とは?
特定のデータパターン(例:マイナンバーの形式、クレジットカード番号の形式)を識別するためのルールやアルゴリズム。(複数のルールを設定することも可能)
「分類プロファイル (Classification Profile)」とは?
検出したいデータの種類に応じて、複数の分類子を組み合わせたもの。例えば、「個人情報」という分類プロファイルには、氏名、住所、電話番号、メールアドレスなどを検出するための分類子が含まれる。
企業はこれらの分類子と分類プロファイルを組み合わせることで、必要に応じて、様々なデータを検出できます。
OneTrust Data Discovery では、「分類子」「分類プロファイル」以外に、主な構成要素として「データソース」と「スキャンプロファイル」があります。
「データソース」とは、MS SQL Server、Amazon S3、Salesforce等のデータベース、ファイルサーバー、クラウドストレージ、SaaS等のスキャン対象に対する情報をまとめたもので、資格情報(※1)やスキャン頻度などのスキャンに必要な情報が含まれます。また、対象データソースに対する過去のスキャン結果やスキャンの結果判明したデータベースのテーブル等の構造やスキーマ、ファイルフォルダのフォルダ構成やファイル情報、関連するアセット(詳細は後述)等もここで見ることができます。
(※1)正確には、対象データソースへのアクセスのための資格情報は、OneTrustに保存されるのではなく、お客様ご指定のVaultサービスに保存され、「データソース」には、そのVaultの参照箇所の情報だけが保存されます。この仕組みにより、セキュリティが強化され、OneTrustが情報漏洩の起点になること防ぎます。
「データソース」とは?
スキャン対象に対して、資格情報(※1)やスキャンの頻度などのスキャンに必要な情報をまとめたもの。スキャン結果やスキャンで判明したスキャン対象の詳細情報も見ることができる。
さらに、(これが OneTrust の強みですが)プライバシー対応、委託先リスク管理、ITセキュリティリスク管理、AIガバナンスなどの他のモジュールで管理しているITアセットと紐づけることで、ユースケースを横断した一元的・統合的なリスク管理を可能にします。具体的には、OneTrust Data Discovery で個人情報や機密情報が検出された場合に、関連する項目やレコードにリスクのフラグを上げたり、自動的に関係者に通知を送ったりすることができます。
また、「スキャンプロファイル」は、(MS SQL、My SQL、MongoDB、Amazon Redshift、SMB、BOX、Salesforce、Slack等の)対象データソースの種類ごとに定義されるもので(同じ種類の対象データソースで複数のスキャンプロファイルを作成可能)、データベースであれば、全体のどのくらいの割合をスキャンするか(スキーマ数、テーブル数、行数の割合、最大行数等の指定)、テーブルか?ビューか?の指定、含める(もしくは除外する)ファイルタイプ(拡張子)、含めるパスや除外するパスの指定等、また、ファイルフォルダであれば、対象ファイルサイズ(上限、下限)や差分スキャンかどうか、OCRの有無、含める(もしくは除外する)ファイルタイプ(拡張子)、含めるパスや除外するパスの指定等のスキャン方法の詳細をまとめたものになります。
「スキャンプロファイル」とは?
対象データソースの種類ごとに、スキャンするオブジェクトの数、割合、サイズ、種類、パス などのスキャン方法の詳細をまとめたもの。
さらに、検出されたデータが実際に探しているデータと一致するかどうかを確認するための承認プロセスが用意されています。このプロセスは、手動または自動で実行でき、組織のデータ資産を効率的かつ一貫性を持って分類・管理するために役立ちます。
マイナンバー検出の設定
OneTrust Data Discoveryでマイナンバーを検出するための設定は、実はとても簡単です。
今回は、以下の手順で設定を行いました。
構成と準備
まずは、検証環境として、以下のものを準備しました。
- OneTrust Data Discoveryの環境構築 (設定手順は、別の記事でご紹介する予定です。)
- テスト用Microsoft SQL Serverにダミーデータを投入
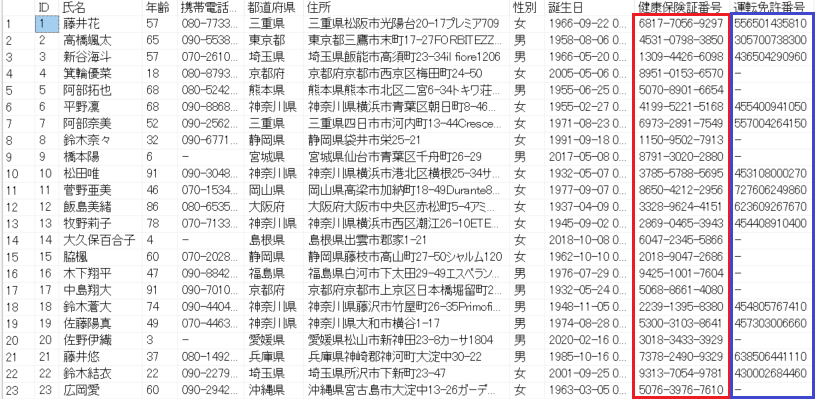
ダミーデータには、意図的に、下図赤枠の健康保険証番号カラムに12桁の数字(実はマイナンバーの番号が入っています。)と、青枠の運転免許証番号カラムにもマイナンバーと誤認しやすい12桁の数字を入れています。
以下のようなダミーデータを1000件ほど用意しました。(入力されているデータはすべて架空のものです。)
検出条件の設定
検出条件の設定
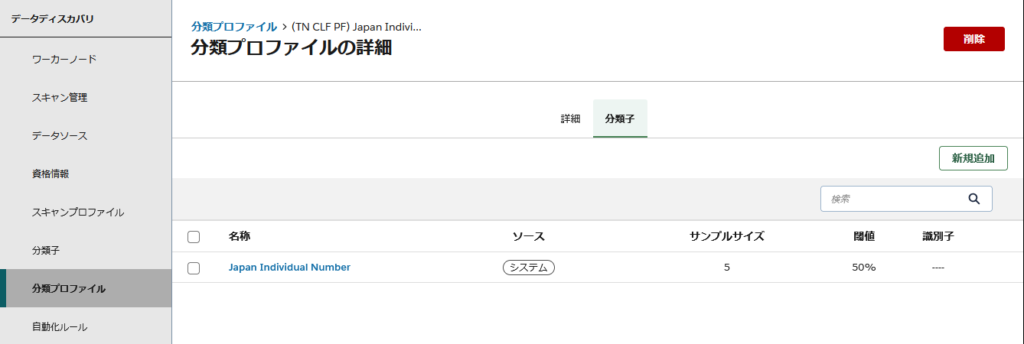
検索の条件を設定します。スキャン対象とするデータの種類や検出パターンを定義するために、「分類プロファイル」を設定します。OneTrustには、マイナンバーをはじめ、クレジットカード番号、メールアドレス、電話番号など、様々な個人情報や機密情報に対応した分類子が予め用意されています。 これらの分類子を利用することで、複雑な設定を行うことなく、様々なデータを検出できます。
また、これらの用意された分類子をそのまま利用するだけでなく、必要に応じてカスタマイズしたり、独自の分類子を作成したりすることも可能です。
今回の検証では、あらかじめ用意されている「Japan Individual Number(マイナンバー)」の分類子を分類プロファイルに設定しました。
スキャンする対象のデータソースを選択
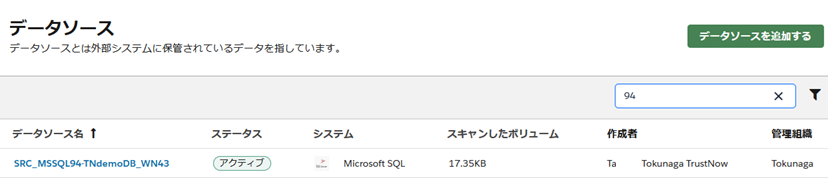
OneTrust Data Discovery では、SQL Server以外にも、様々なデータベースやファイルサーバー、クラウドストレージなどをスキャン対象(データソース)として指定できます。今回の検証では、先ほどダミーデータを投入したMicrosoft SQL Serverをデータソースとして選択しました。
手動でスキャンを実行
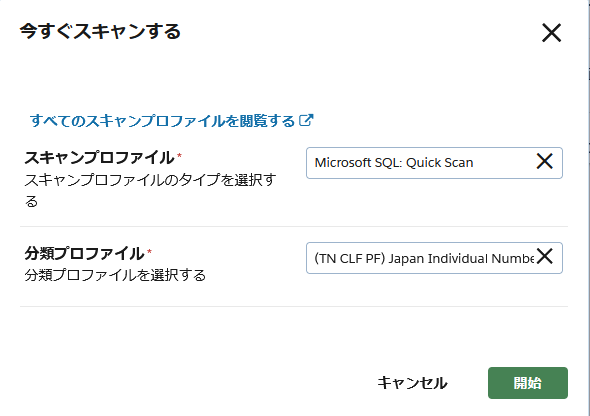
検出の条件(分類プロファイル)とデータソースの設定が完了したら、いよいよスキャンを実行します。
データソースを選択し、そこからスキャンプロファイルと分類プロファイルを選択して実行します。 スキャンは、手動で実行する以外にも、スケジュールを設定して定期的に実行することも可能です。
マイナンバー検出の結果
設定を終え、いよいよマイナンバーのスキャンを実行しました。
スキャン結果を確認したところ、対象のデータソースからマイナンバーらしき情報が1か所で検出されています。こちらのカウント数はデータソースごとにカウントされます。
誤検出を防ぐため、まずは検出されたデータをレビューして、正しく検出が行われているか?(この情報が本当にマイナンバーであるか?)を確認します。
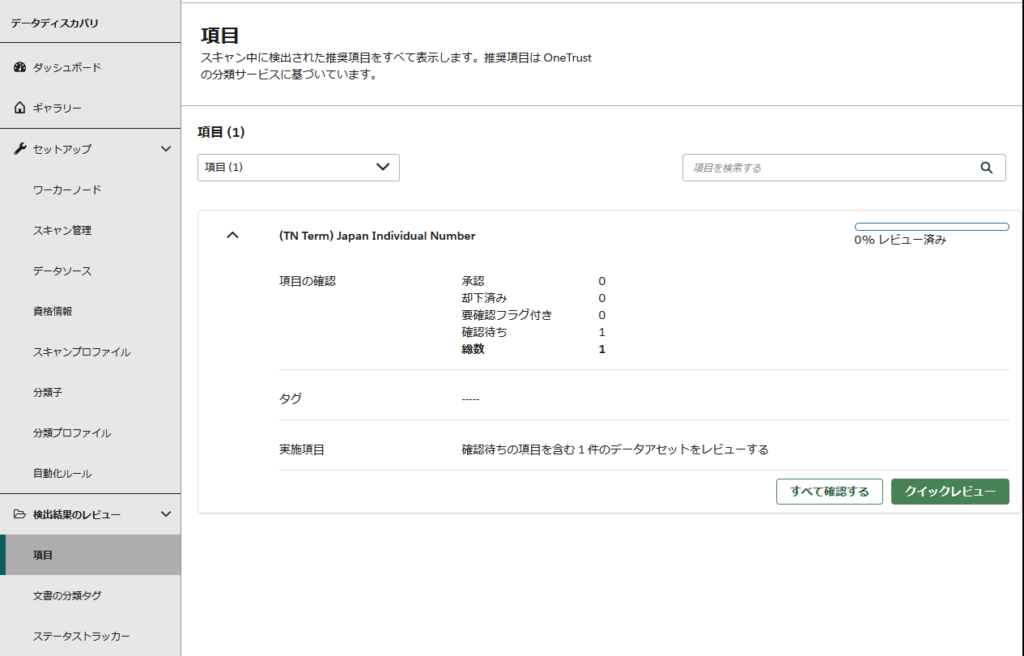
「クイックレビュー」ボタンをクリックすると、マイナンバーの可能性があるデータのサンプルや検出箇所などの詳細が確認できます。
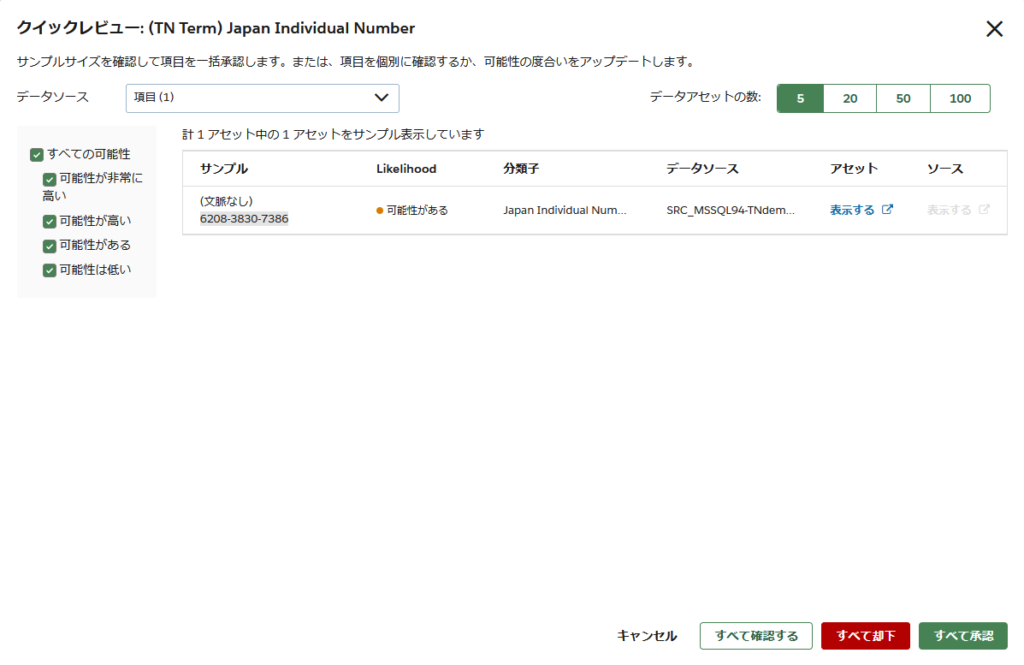
サンプルや検出箇所などの詳細を確認したら、OneTrust Data Discoveryが提案してきた内容を「承認」します。(上記画面は、複数の項目を一括承認する操作なので、ボタンの表示が「すべて承認」になっていますが、個別の項目ごとに承認することも可能です。その場合は下記の画面になります。)
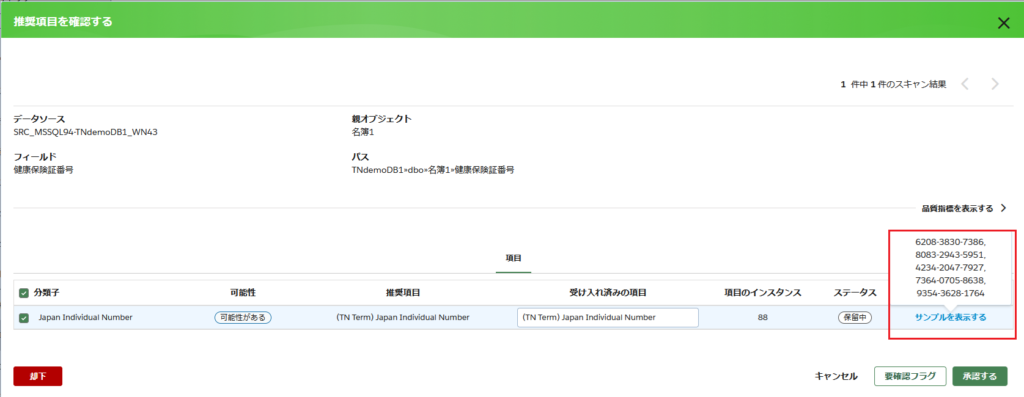
用語の承認について
ここで行う「承認する」ボタンを押す行為は、OneTrust Data Discoveryが自動的に検出したデータとその分類(用語)を確認して正式に採用するプロセスです。
用語の承認プロセスを簡単に説明すると:
提案
OneTrustが対象データソースをスキャンし、「これはマイナンバーかもしれない」用語(分類ラベル)を自動的に提案します。
確認
管理者やユーザーがこれらの提案を確認します。(多数の提案を一括で承認/却下することも可能です。)
正しい提案 → 「承認」
このフィールドは正式に「マイナンバー」用語として定義され、関連するポリシーやガバナンスルールが適用されます。
間違った提案 → 「却下」
提案は無視され、そのフィールドは「マイナンバー」とは見なされません。
このプロセスを通じて、組織のデータ資産を効率的かつ一貫性を持って分類・管理できるようになります。
サンプルデータの検証
念のため、サンプルとして抽出されたデータが、実際にデータベース内に存在するかどうかを確認しました。サンプル1行目の「6208-3830-7386」をデータベース内で検索したところ、データが存在することを確認できました。

次は、OneTrustのデータカタログのデータディクショナリからも、検出結果を確認してみましょう。
データディクショナリを使用すると、Microsoft SQL Serverのどのテーブルのどのカラムに個人情報が含まれているかを容易に把握できます。
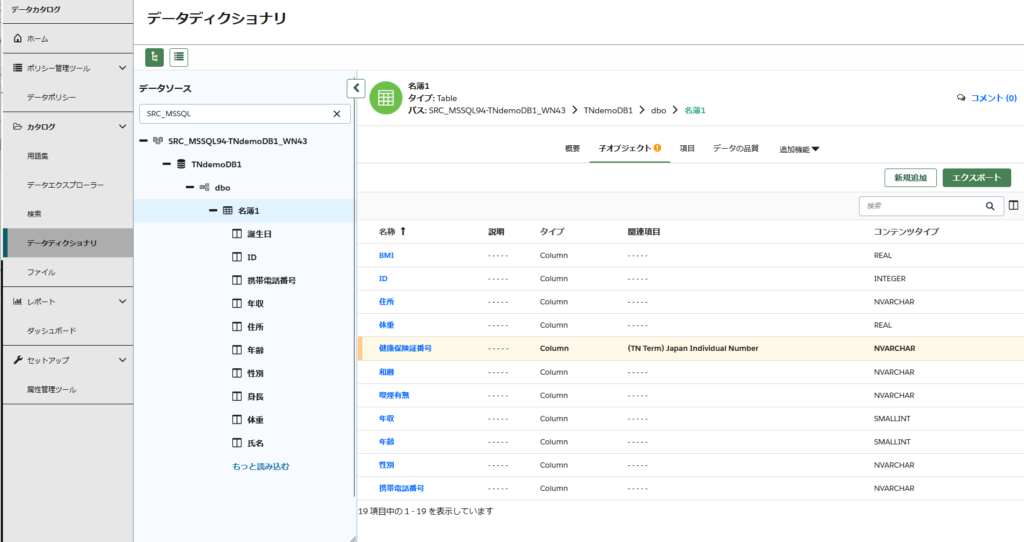
類似するデータ形式を識別し、正確なマイナンバーを検出

データ検出において重要なのは、ノイズとなる類似データを排除し、真に検出したい情報を正確に特定する能力です。今回、OneTrust Data Discovery が、12 桁の運転免許証番号をマイナンバーとして誤検出しなかったこと、そして、誤ったカラム名「健康保険証番号」に入っていたマイナンバーを検知したことに注目したいと思います。
運転免許証番号もマイナンバーと同じ 12 桁の数字であるため、単純なパターンマッチングでは誤って検出される可能性があります。しかし、OneTrust Data Discovery は、予め用意された分類子と用語の承認機能により、これらの類似データを正確に区別し、組織全体でデータの理解と定義を統一することを可能にしました。
この事例では、運転免許証番号の形式的な類似性にもかかわらず、OneTrust Data Discovery はこれをマイナンバーと識別し、正確にマイナンバーのみを検出することに成功しました。これは、OneTrust Data Discovery が、単なる桁数の一致だけでなく、データに含まれるパターンを正しく理解し、より精密な検出を行っている証と言えるでしょう。さらに、OneTrust Data Discovery は、誤ったカラム名である「健康保険証番号」に入力されていたマイナンバーも正確に検出しました。これは、カラム名だけでなく、データの内容そのものを解析する能力を示しています。
このように、OneTrust Data Discovery は、類似性の高いデータが混在する環境においても、誤検出のリスクを低減し、機密性の高い個人情報であるマイナンバーを正確に特定・管理するための強力なソリューションとなります。
終わりに
OneTrust社の Data Discoveryは、企業の皆様が抱えるデータ管理の課題を解決するための強力なツールです。
- 効率的な情報検出: 高度な検出機能と細かくカスタマイズ可能な検出条件の設定により、必要な情報を迅速かつ正確に特定します。
- 容易な設定: マイナンバーやクレジットカード番号など、一般的な個人情報や機密情報を検出するための分類子が豊富に組み込まれており、複雑な設定なしにデータ検出を開始できます。
- 多様なデータソース対応: Microsoft SQL Server をはじめ、Snowflake、Salesforce、SAP、Box、AWS S3、Google Drive、OneDrive など、様々なデータベース、ファイルサーバー、クラウドストレージを横断的に検索できます。
- 正確なデータ所在の把握: 検出されたデータの保存場所をデータディクショナリで確認できるため、データの所在を正確に把握し、適切な管理と保護を行うことができます。
今回の検証結果から、OneTrust Data Discoveryは、企業の皆様のデータ管理戦略において、有効に活用できることがお分かりいただけたかと思います。
OneTrust Data Discoveryにご興味をお持ちでしたら、お気軽にお問い合わせください。弊社が、お客様のニーズに合わせた最適なソリューションをご提案いたします。

OneTrust は、プライバシー分野でNo.1のソリューションです。
プライバシー法規制の要求事項について包括的に対応している点が人気の理由です。
OneTrustのソリューションに興味がありましたら、
お気軽にお問い合わせください
